K3s Branch Sandboxing: Automating EC2 Infrastructure with GitHub Actions, Terraform, Helm & Cloudflare
· 20 min read

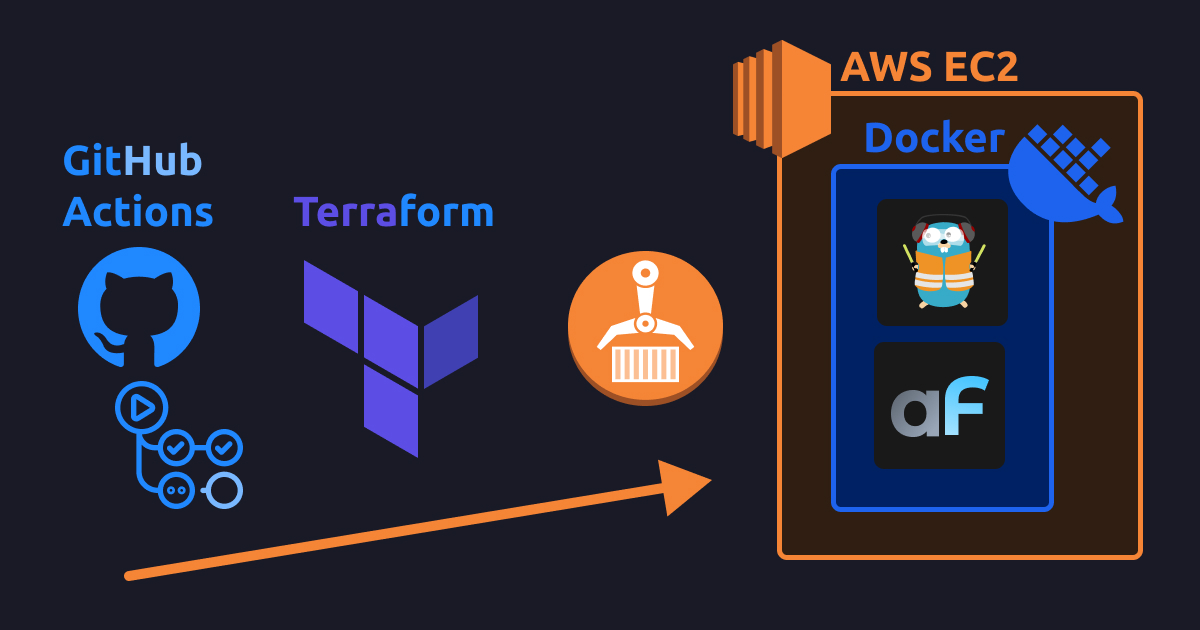
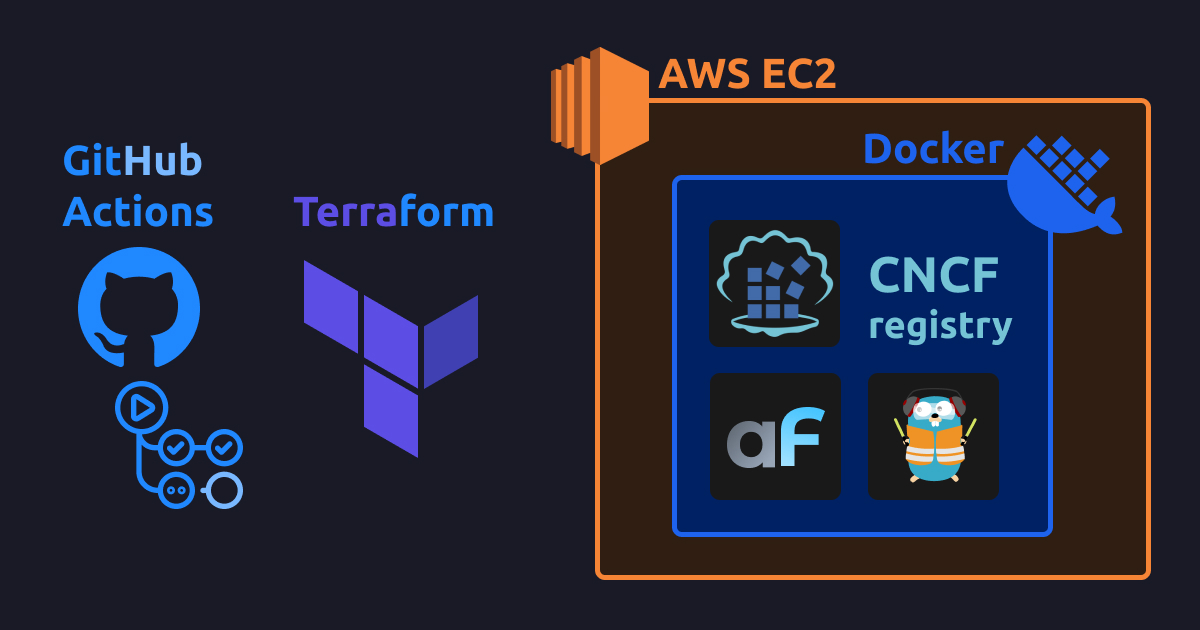
“Branch-based sandboxing” is a revolutionary approach to development that allows teams to create isolated environments—as close as possible to production—for each feature branch. This ensures that code changes are tested under realistic conditions before being merged into the main branch, which helps avoid issues like “it works on my machine” and ensures deployment stability. The implementation described in this post covers the automatic creation of an isolated development/testing environment using the resources of an existing EC2 instance, as well as the scaling of those resources in the event of a shortage.
This guide covers:
- Automated EC2 infrastructure provisioning using Terraform
- K3s cluster installation and setup on EC2
- Cloudflare DNS management for custom domains
- GitHub Actions workflows for automated deployments and cleanup
- Monitoring and management practices